Multinode jobs and topology
In jobs, you can also request jobs that span over two or more nodes, these are called multinode jobs and have special things to consider when running them.
You can request jobs that have different "shapes", such as the layout of the following command:
Here, the job encompasses two nodes, with two tasks on each node, and 64 cores assigned to each task. The layout looks like this: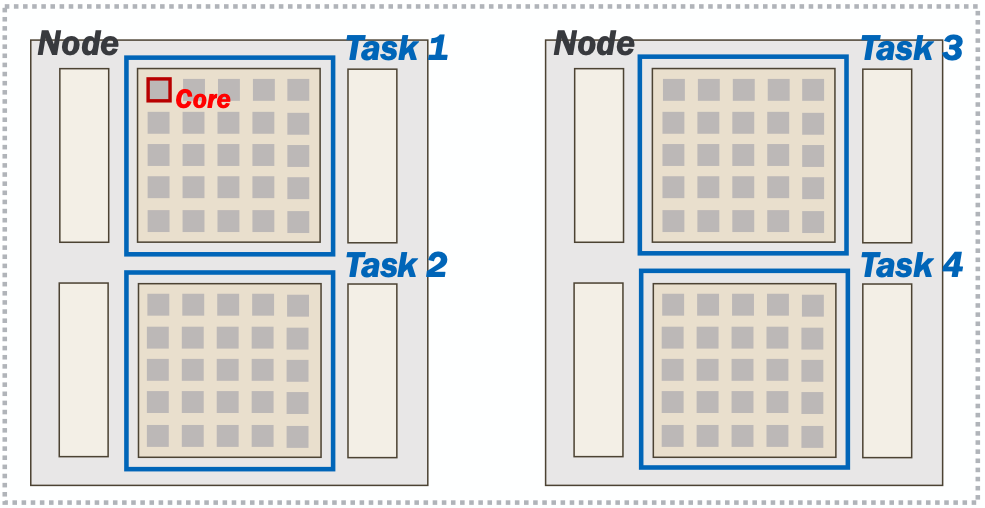
As mentioned earlier, the hostname program prints out the hostname of the server we are currently on.
The srun launcher is part of Slurm and will bring up copies of your program within the allocation according to the number of tasks in your request.
Submit the following job script (or variations of it) to get a sense of how we can launch copies of a program across an allocation. Name the job script hostname.sh
| hostname.sh | |
|---|---|
Submit your job to the scheduler using the sbatch program:
squeue --me:
$ squeue --me
JOBID USER ACCOUNT NAME NODES CPUS TIME_LIMIT ST TIME
19804935 username lab_queue hostname.sh 2 256 00:10:00 PD 00:00
squeue --me, that's because your job already finished. If this happens, use the job ID that was put out by the sbatch command.
Remember that the job ID will be used for the output filename (e.g. slurm-19804935.out). You can use the cat program to show the output stored in the file:
$ cat slurm-19804935.out
a200.negishi.rcac.purdue.edu
a200.negishi.rcac.purdue.edu
a209.negishi.rcac.purdue.edu
a209.negishi.rcac.purdue.edu
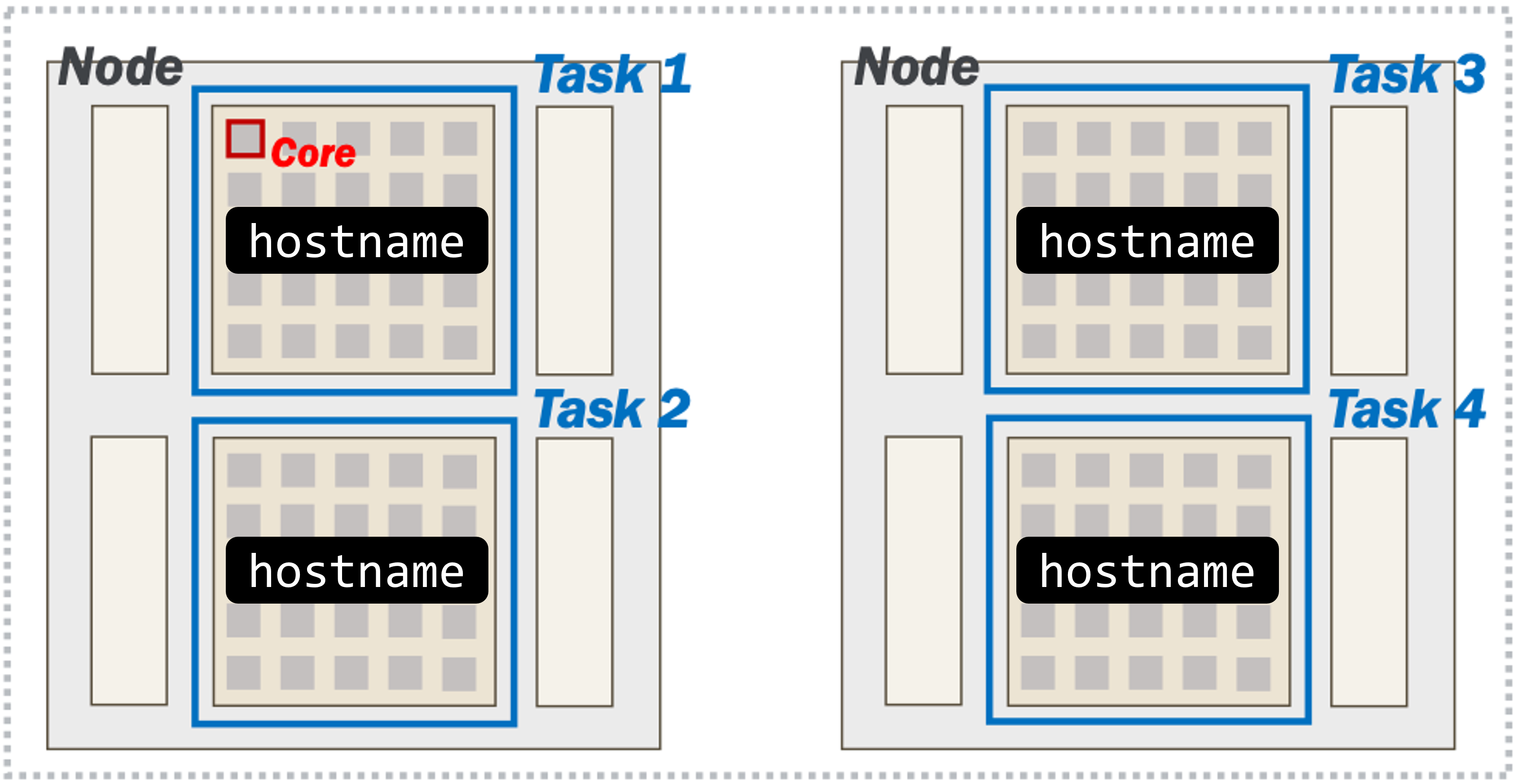
What did you notice in the output file of this job? Do the hostnames align with what you expected based on the request?
Yes! We requested 2 nodes, each with 2 tasks (for 4 tasks total). srun runs the hostname program in each of our tasks. We can see that two of the tasks were launched on a200, and the other two were launched on a209.
Separating Outputs
You can use srun's --output option to separate the output if the individual tasks:
%j is the job ID, %t is the task ID and %s is the step ID.
We cannot go too deep into the nuances of distributed software development or MPI-based applications in this workshop. However, it is still important to understand that your job script does not automatically start running on other nodes in your job.
But, we've learned that it is possible to orchestrate multiple tasks in parallel across nodes.
Next section: Congratulations!